
A lot of AI workflows look brilliant in a demo and then quietly fall apart on a Tuesday afternoon.
Not because the model is "bad". Because the workflow assumes conditions your team almost never has: complete context, stable priorities, clean data, and a human who replies instantly with a crisp yes/no.
If you're on a 5–20 person product or GTM team, you'll recognise the pattern immediately. Someone asks an agent to draft a spec, write a customer email sequence, or triage inbound leads. The agent produces something fast. For a moment, it feels like relief.
Then the real work begins.
People hunt for missing context. Contradictions appear across tools. Approvals stall. Outputs get reworked because the underlying decision changed while everyone slept. What looked like speed turns into a longer review cycle than before.
The operational pain is rarely dramatic. It's death by small frictions. Decisions live in a Slack thread, a half-updated Notion page, and a Jira comment from last week. An agent "finishes" its task, but nobody is clearly responsible for the next step. Legal, finance, or a busy founder becomes the bottleneck, and the team is spread across time zones.
When AI-driven workflows fail in this environment, it's tempting to blame the model. In practice, most failures are simpler and more stubborn. They come from idealised assumptions about how work actually happens.
Key Takeaways
- Most AI tools are designed for ideal conditions, not real team workflows.
- Missing context doesn't just slow teams down; it compounds rework and coordination debt.
- Human delays and async approvals are normal operating conditions, not edge cases.
- Speed without adaptability doesn't save time, it pushes the cost downstream.
- Good agents help work complete by pausing, clarifying, escalating, and recovering when reality intervenes.
The "perfect workflow" myth
Most AI tools are built around an idealised picture of work. Inputs are complete. Steps are linear. Decisions are instant. Integrations behave exactly as expected. This isn't malicious; it's convenient. It's also why those workflows collapse the moment real people touch them.
Demos mirror how leaders want work to happen: clear inputs, tidy handoffs, clean outputs. You see "final PRDs", stable pipelines, and instant approvals. In five minutes, the workflow reaches a satisfying conclusion.
But early-stage teams don't buy AI tools because their workflows are already clean. They buy them because they're under pressure. Headcount is tight. Hiring feels slow and risky. Shipping, revenue, and pipeline targets don't wait.
Speed becomes the purchase criterion. If an agent can generate a PRD, a campaign outline, or a report in seconds, it looks like a shortcut around resourcing. For a brief period, that belief holds. Drafts appear. Summaries land. Work feels lighter.
Then friction shows up in the seams. Reviews drag. Outputs bounce back. Someone asks which version is correct. Another person flags that the CRM field isn't reliable. A stakeholder points out that positioning changed yesterday.
The agent isn't failing at language. It's failing at coordination.
Where idealised workflows break in real teams
In real teams, breakdowns tend to cluster around a small number of predictable patterns. The good news is that these aren't edge cases. They're normal operating conditions.
Missing context
Context almost never lives in one place. Decisions are scattered across Slack threads, meeting notes, ticket comments, CRM records, and half-written documents that never quite became "official". Important constraints are often informal and unstructured: "Legal were nervous about this last time" or "We promised this customer we wouldn't do that again."
A common product scenario looks like this: an agent drafts a PRD from a meeting transcript. It includes requirements that were described as tentative. Later, a Jira comment narrowed scope. Acceptance criteria live in a Figma annotation. Edge cases were discussed in a Slack thread with support. Unless the agent is explicitly guided, it can't see the contradictions.
Downstream, engineering reviews the spec and flags gaps. The document bounces back. The agent is asked to "update it", but now there are multiple versions and no agreed baseline.
The same pattern shows up in GTM work. An agent drafts outbound messaging based on last quarter's positioning doc. Meanwhile, the website headline changed last week and sales is using a different talk track. The output is fast, but misaligned, so the review cycle expands.
Shifting priorities
Small teams change direction constantly. A founder call reshapes the roadmap. A key customer escalates a bug. A competitor launches a feature. The backlog is reordered.
Idealised workflows assume stability: gather inputs, produce output, ship. Real workflows are iterative. Work often sits in limbo while priorities are renegotiated.
If an agent can't detect that the world changed, its "finished" output becomes stale mid-flight. Teams either ship the wrong thing or spend time manually auditing every line to figure out what still applies.
Ownership gaps and handoffs
Most work doesn't fail because nobody can write. It fails because nobody can decide.
Ownership is often fragmented across tools. In Notion, the PM is listed. In Jira, the EM is the assignee. In Slack, the founder is making calls. The agent completes a task, but no one is clearly accountable for the next decision.
In GTM teams, the same thing happens with inbound leads and campaigns. CRM fields are inconsistent. Routing rules change as the team learns. Without clear ownership and escalation paths, the agent either pushes work forward incorrectly or creates a queue of "needs review" that nobody owns.
Work looks done, but it can't move forward.
Human delays are the operating system
Most workflow tools treat waiting as failure. In reality, waiting is the system.
Approvals, reviews, stakeholder availability, and time zones stretch work into long tails. In async teams, a question asked late in the day in London might not be answered until the next morning by someone in San Francisco.
This isn't hypothetical. Research in interruption science shows that knowledge workers are interrupted roughly every 6–12 minutes, fragmenting focus and quietly turning coordination into a tax that compounds across the day.
Waiting also changes the state of the world. While you're waiting for legal sign-off, a competitor might announce something, a customer might escalate, or a stakeholder might change their mind.
Naive automation responds badly to delay. It either acts without permission, creating risk, or stalls silently, creating confusion. Blocked work turns into hidden queues. Threads get reopened. Clarification loops repeat.
Good systems tolerate delay and make it visible. They surface what's blocked, who owns the next decision, and when escalation should happen. Waiting isn't eliminated; it's managed.
Why adaptability matters more than speed
Speed is attractive because it's easy to measure and easy to sell. Faster execution feels like progress. But faster execution of wrong assumptions doesn't create leverage; it multiplies errors.
A fast but brittle agent produces drafts that trigger long review cycles. People argue about assumptions. Someone notices a missing constraint late. Revisions introduce new inconsistencies because the underlying context was never stabilised. Adaptability is what actually saves time.
Adaptable agents pause when inputs are insufficient. They ask targeted clarifying questions instead of a vague "need more context". They escalate decisions to the right owner instead of guessing. They recover cleanly when priorities change.
That pause can feel like friction. In practice, it reduces total coordination time. It also reduces the emotional cost: fewer "why did you do that?" moments, fewer late-night fixes, fewer awkward customer corrections.
Speed still matters, but only when applied to the right things: low-risk repeatables, verification steps, and status updates. When speed outpaces governance, teams pay in rework and lost trust.
The demo wiring trap
You can see this same mistake in how many "agent" systems are wired today: they optimise for what works when a human is watching, not what keeps going when nobody is.
A common approach is to rely on pre-packaged tools and prompt packs, often exposed through things like Model Context Protocols. These work well when there's a human actively driving the interaction: selecting tools, correcting mistakes, and re-prompting when something goes sideways.
The trade-off shows up when you try to run that setup unattended. Loading large sets of tools upfront increases context overhead, wastes tokens on instructions that aren't needed for the task at hand, and introduces failure modes you don't control because those tools are maintained elsewhere.
That's fine for interactive productivity. It's brittle for long-running automation, where precision, context efficiency, and predictable behaviour matter more than feature count. The system isn't failing because the model is weak, it's failing because the workflow assumes a human will be there to notice and correct the deviation.
What you should expect a good agent to do
A good agent doesn't pretend it has the full picture. It assumes context is partial, sometimes wrong, and often out of date. So it checks where decisions actually live before acting. When the source of truth is unclear, it surfaces the gap instead of quietly filling it in with guesswork.
It doesn't make decisions by accident. When judgement or approval is required, it routes the question to the right owner with enough context to respond quickly and with a clear recommendation, rather than dumping an open-ended ask into someone's inbox and calling that progress.
It's designed for async reality. People are offline. Approvals take time. Silence is not consent. Waiting states are explicit, follow-ups are intentional, and stalled work doesn't disappear quietly into the system.
It respects governance without turning everything into ceremony. Drafting is cheap. Execution isn't. A good agent knows the difference, avoids high-risk actions without sign-off, and leaves a trail humans can actually follow when something changes.
And when things get ambiguous, it doesn't power through. It pauses, flags uncertainty, and hands off cleanly. The goal isn't to look decisive, it's to avoid creating rework, risk, or cleanup later.
That's what "moving work forward" looks like in practice: not perfect automation, but fewer stalled handoffs, fewer clarification loops, and fewer silent failures that only show up days later.
Put differently: if an agent looks impressive in a demo but can't do these things consistently, it's not reducing work, it's just moving the mess around faster.
The reality-ready execution checklist
Use this as a lens for evaluating agent behaviour in real workflows.
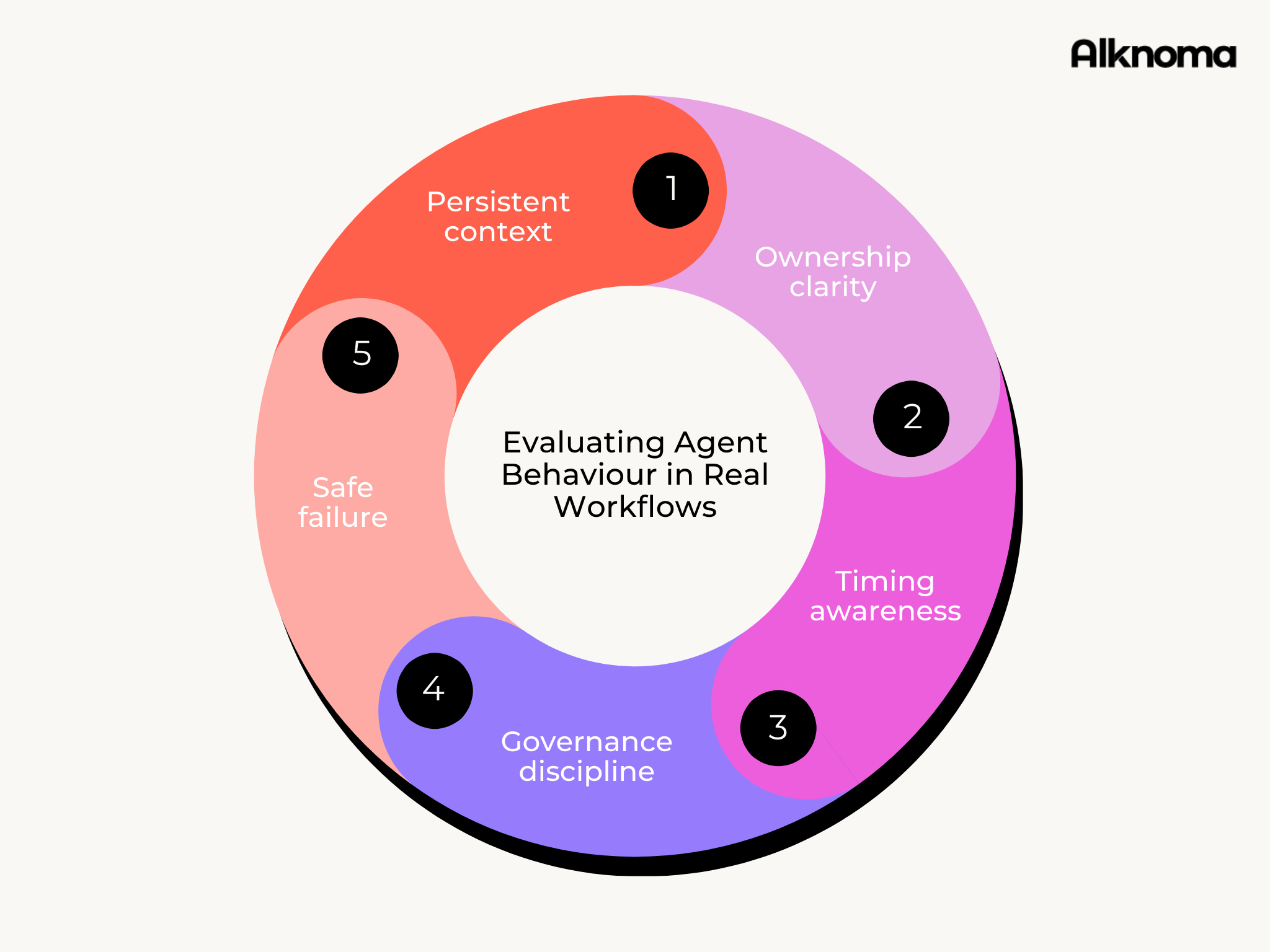
Five criteria for evaluating whether an agent can handle real-world team workflows.
Persistent context — Does it work from current, agreed sources of truth and clearly signal when the context it's using may be stale or incomplete?
Ownership clarity — Does it know who is accountable for decisions and escalate deliberately when ownership is ambiguous, instead of guessing or blocking progress?
Timing awareness — Does it make waiting visible, manage follow-ups, and escalate when work stalls, so delays are handled, not hidden?
Governance discipline — Does it separate drafting from execution and require approval for actions that carry customer, revenue, or compliance risk?
Safe failure — When inputs conflict or uncertainty is high, does it stop, surface the issue, and route it to a human, then improve as the same patterns repeat?
What reality-ready execution looks like
If you work in a small, distributed team, this is worth stopping on for a moment. When people are offline, overloaded, or spread across time zones, does work still move? Or does progress quietly depend on someone being around to chase, clarify, or patch over gaps?
When agents behave well in real conditions, the difference shows up in unglamorous places. Fewer tickets sitting in "needs review" with no clear next step. Fewer clarification loops where the same question gets asked in three different tools. Fewer rewrites caused by context that surfaced too late.
Cycle time becomes more predictable, not because everything is faster, but because waiting is visible and managed. Work doesn't vanish into gaps. Decisions don't get lost between systems. Ownership stays clear even when people aren't immediately available.
The goal isn't more output. It's fewer things getting stuck halfway. That's the gap between AI that looks impressive in a demo and AI that still holds up on a Tuesday afternoon.
That's the problem we're focused on at Alknoma: building agents that adapt to how teams really work, instead of asking teams to contort themselves around brittle, idealised workflows.